Unsupervised Embedding Learning BERT: A Comprehensive Guide
Hey there, data enthusiasts! If you're diving into the world of natural language processing (NLP), you've probably heard about unsupervised embedding learning with BERT. It's like the holy grail of text understanding, making machines smarter and more human-like in their interactions. But what exactly is unsupervised embedding learning BERT, and why should you care? Let's break it down in a way that even your grandma could understand—or at least pretend to! So, grab your favorite snack, sit back, and let's get into it.
Think about how humans process language. We don’t need a dictionary every time we hear a new word. Instead, we figure out meaning based on context, patterns, and experience. Machines, on the other hand, need a little help. That’s where unsupervised embedding learning with BERT comes in. It’s like teaching a robot to think like a human without explicitly spoon-feeding it every single rule. Pretty cool, right?
This guide will walk you through everything you need to know about unsupervised embedding learning BERT. We’ll cover the basics, dive into some technical details, and explore why this approach is so powerful. Whether you’re a beginner or a seasoned NLP expert, there’s something here for everyone. Let’s get started!
Read also:Court Grammar The Ultimate Guide To Mastering Legal Language
What is Unsupervised Embedding Learning BERT?
Unsupervised embedding learning BERT is a game-changing approach in the field of NLP. It allows machines to learn meaningful representations of words and sentences without needing explicit labels. In simpler terms, it’s like letting a machine read a ton of text and figure out how words relate to each other all by itself.
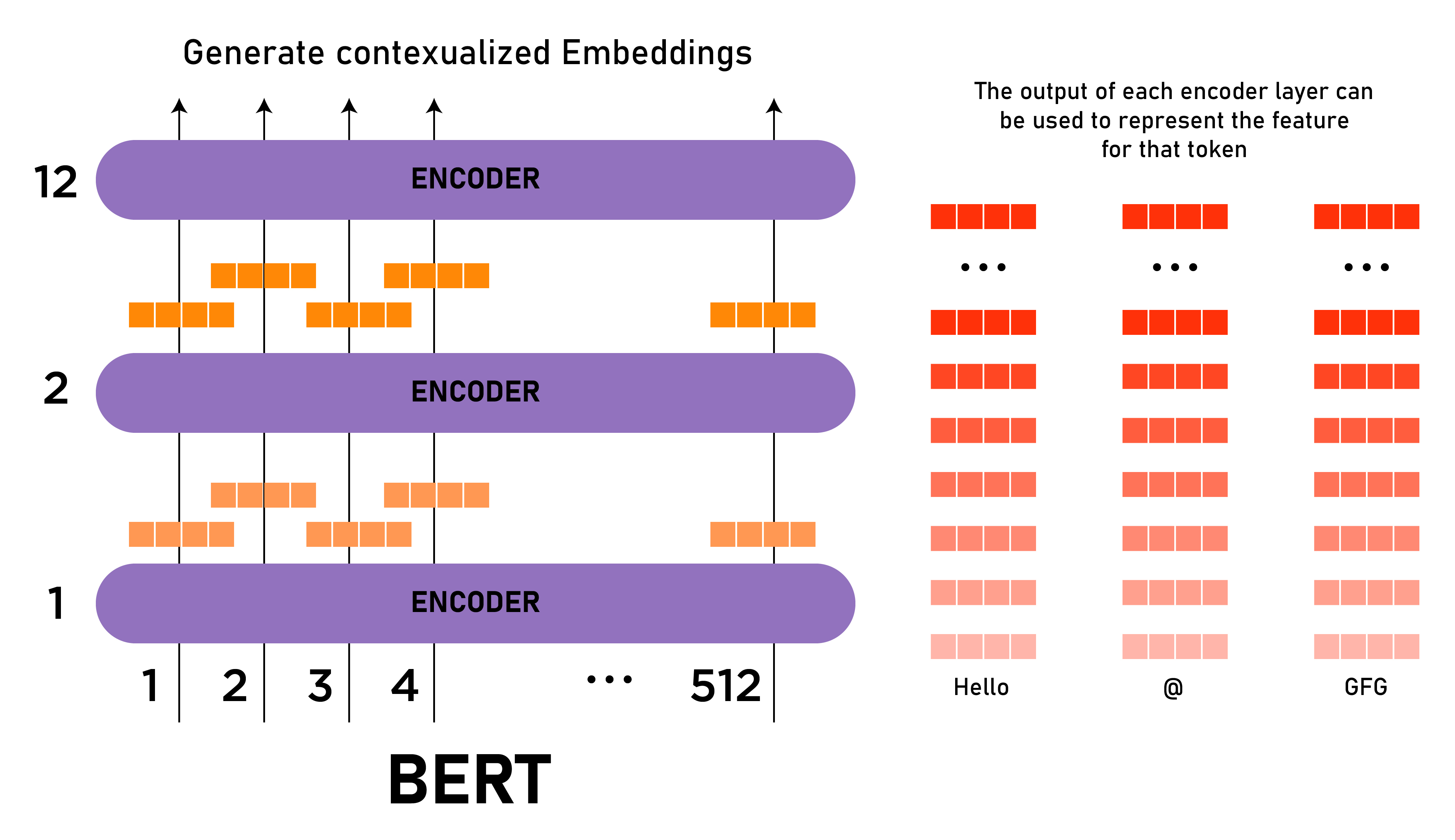
BERT, which stands for Bidirectional Encoder Representations from Transformers, is a pre-trained model developed by Google. It’s designed to understand the context of words in a sentence by looking at both the left and right sides. This bidirectional approach makes BERT incredibly powerful for tasks like question answering, sentiment analysis, and text classification.
When we talk about unsupervised learning, we’re referring to the process where the model learns patterns and structures in the data without being told what to look for. It’s like sending a kid to a playground and letting them figure out how to have fun instead of giving them step-by-step instructions.
Why is Unsupervised Embedding Learning Important?
In the world of machine learning, data is king. But labeled data, which is necessary for supervised learning, can be expensive and time-consuming to gather. That’s where unsupervised learning shines. It allows models to learn from vast amounts of unlabeled data, which is much easier to come by.
Here are a few reasons why unsupervised embedding learning is so important:
- Scalability: With unsupervised learning, you can train models on massive datasets without the need for manual labeling.
- Generalization: Models trained with unsupervised methods often generalize better to new, unseen data.
- Efficiency: Unsupervised learning can be more efficient in terms of both time and computational resources.
When combined with BERT, unsupervised embedding learning becomes even more powerful. The model can learn deep contextual representations that capture the nuances of language, making it highly effective for a wide range of NLP tasks.
Read also:New York Presbyterian Hudson Valley Hospital Photos A Closer Look Inside
How Does BERT Work in Unsupervised Embedding Learning?
BERT works by using a transformer-based architecture to process text. Unlike traditional models that process text sequentially, BERT looks at the entire sentence at once. This allows it to capture the context of each word in relation to all other words in the sentence.
Here’s a quick breakdown of how BERT works:
- Input Representation: BERT takes a sequence of tokens as input, where each token can be a word or a subword. Special tokens like [CLS] and [SEP] are added to indicate the start and end of sentences.
- Transformer Layers: The input is passed through multiple transformer layers, which perform self-attention and feed-forward operations to generate contextual embeddings.
- Output Representation: The output of BERT is a set of contextual embeddings for each token in the input sequence. These embeddings can be used for downstream tasks like classification or regression.
In unsupervised embedding learning, BERT is typically pre-trained on a large corpus of text using tasks like masked language modeling (MLM) and next sentence prediction (NSP). This allows the model to learn general language representations that can be fine-tuned for specific tasks.
Key Components of BERT
To better understand how BERT works, let’s take a closer look at its key components:
- Encoder: The encoder is responsible for generating contextual embeddings. It consists of multiple transformer layers that perform self-attention and feed-forward operations.
- Self-Attention Mechanism: Self-attention allows the model to weigh the importance of different words in the sentence when generating embeddings for each token.
- Feed-Forward Networks: After the self-attention step, the embeddings are passed through feed-forward networks to further refine them.
These components work together to create rich, contextual representations of text that capture both local and global dependencies.
Applications of Unsupervised Embedding Learning BERT
The applications of unsupervised embedding learning with BERT are virtually endless. Here are just a few examples:
- Question Answering: BERT has been used to achieve state-of-the-art performance on question answering tasks like SQuAD.
- Sentiment Analysis: By fine-tuning BERT on sentiment datasets, models can accurately classify the sentiment of text.
- Text Classification: BERT can be used for tasks like spam detection, topic classification, and more.
- Machine Translation: While BERT itself is not a translation model, its embeddings can be used as input to machine translation systems to improve performance.
These applications demonstrate the versatility and power of BERT in understanding and processing natural language.
Challenges in Unsupervised Embedding Learning
While unsupervised embedding learning with BERT offers many advantages, it’s not without its challenges. Here are a few things to keep in mind:
- Computational Resources: Training large models like BERT requires significant computational resources, including powerful GPUs or TPUs.
- Data Quality: The quality of the pre-training data can have a big impact on the performance of the model. Garbage in, garbage out, as they say.
- Fine-Tuning: Fine-tuning BERT for specific tasks can be tricky and may require careful tuning of hyperparameters.
Despite these challenges, the benefits of unsupervised embedding learning with BERT often outweigh the drawbacks, especially for complex NLP tasks.
Overcoming Challenges
Here are a few strategies for overcoming the challenges of unsupervised embedding learning:
- Use Pre-Trained Models: Instead of training BERT from scratch, you can use pre-trained models and fine-tune them for your specific task.
- Data Augmentation: Techniques like data augmentation can help improve the quality of your training data.
- Hyperparameter Tuning: Experiment with different hyperparameters to find the optimal settings for your task.
By leveraging these strategies, you can maximize the performance of your models while minimizing the challenges.
Comparing Unsupervised Embedding Learning with Other Approaches
Unsupervised embedding learning with BERT is just one of many approaches to NLP. Let’s compare it to some other popular methods:
- Word2Vec: Word2Vec is a simpler model that generates word embeddings based on co-occurrence patterns. While effective for some tasks, it doesn’t capture contextual information as well as BERT.
- ELMo: ELMo (Embeddings from Language Models) is another approach that generates contextual embeddings. However, it’s unidirectional, meaning it only looks at the left or right context, not both.
- GPT: GPT (Generative Pre-trained Transformer) is similar to BERT but uses a unidirectional architecture. This makes it better suited for tasks like text generation but less effective for tasks requiring bidirectional context.
Each of these approaches has its own strengths and weaknesses, and the best choice depends on the specific task and requirements.
Future Directions in Unsupervised Embedding Learning
The field of unsupervised embedding learning is rapidly evolving, and there are many exciting developments on the horizon. Some potential future directions include:
- Multi-Modal Learning: Combining text with other modalities like images or audio to create richer representations.
- Efficient Models: Developing more efficient models that require less computational resources while maintaining or improving performance.
- Federated Learning: Using federated learning to train models on decentralized data, preserving privacy and security.
These advancements could further enhance the capabilities of unsupervised embedding learning and open up new possibilities for NLP applications.
What’s Next for BERT?
BERT itself is also evolving, with newer versions like RoBERTa, ALBERT, and ELECTRA building on its success. These models aim to improve efficiency, scalability, and performance while maintaining the strengths of the original BERT architecture.
As research continues, we can expect even more powerful and versatile models that push the boundaries of what’s possible in NLP.
Conclusion
Unsupervised embedding learning with BERT is a powerful approach that’s transforming the field of NLP. By allowing machines to learn meaningful representations of text without explicit labels, it opens up new possibilities for a wide range of applications. From question answering to sentiment analysis, the potential is virtually limitless.
While there are challenges to overcome, the benefits of unsupervised embedding learning far outweigh the drawbacks. As the field continues to evolve, we can expect even more exciting developments that will further enhance the capabilities of NLP systems.
So, what are you waiting for? Dive into the world of unsupervised embedding learning with BERT and see what you can create. And don’t forget to share your thoughts and experiences in the comments below. Let’s keep the conversation going!
Table of Contents
- What is Unsupervised Embedding Learning BERT?
- Why is Unsupervised Embedding Learning Important?
- How Does BERT Work in Unsupervised Embedding Learning?
- Applications of Unsupervised Embedding Learning BERT
- Challenges in Unsupervised Embedding Learning
- Comparing Unsupervised Embedding Learning with Other Approaches
- Future Directions in Unsupervised Embedding Learning
- Conclusion



, you've probably heard about unsupervised embedding learning w){kind=link}