Serializable Spark Read: Mastering Data Processing With Ease
Are you ready to dive deep into the world of Spark and data processing? Serializable Spark Read is the key to unlocking powerful insights and making your data workflows smoother than ever before. In today’s fast-paced digital landscape, understanding how Spark handles serialization is no longer just an option—it’s a necessity. Whether you’re a data engineer, a developer, or someone simply curious about big data technologies, this article will guide you through everything you need to know.
Now, let’s face it: working with big data can be overwhelming. You’ve got terabytes of information coming at you from all directions, and you need a tool that can handle it all without breaking a sweat. That’s where Spark comes in. But here’s the thing—if you’re not careful about how you read and process your data, things can get messy real quick. Serializable Spark Read is the solution to that problem, ensuring your data flows seamlessly through your pipelines.
This article isn’t just another tech blog post. It’s your go-to guide for mastering Spark serialization, complete with practical tips, real-world examples, and actionable insights. By the end of it, you’ll be equipped with the knowledge to optimize your Spark jobs like a pro. So, buckle up and let’s get started!
Read also:Best Size For Instagram Photos Your Ultimate Guide To Perfectly Scaled Posts
Here’s a quick sneak peek of what we’ll cover:
- What is Serializable Spark Read?
- Why Serialization Matters in Spark
- Spark Serialization Mechanisms
- Optimizing Spark Serialization
- Common Pitfalls to Avoid
- Best Practices for Serializable Spark Read
- Real-World Examples of Serializable Spark Read
- Tools for Monitoring Serialization Performance
- Future Trends in Spark Serialization
- Conclusion: Take Your Spark Skills to the Next Level
What is Serializable Spark Read?
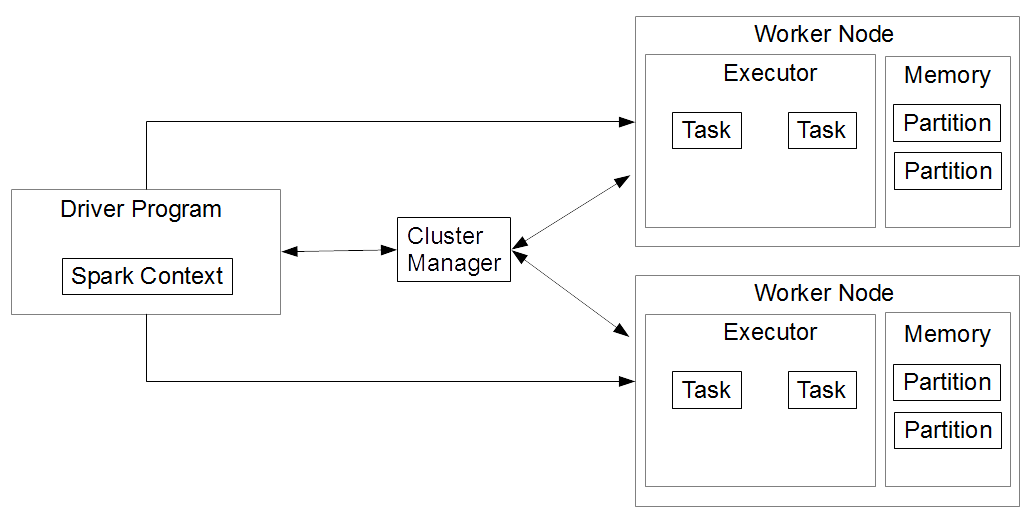
Alright, let’s break it down. Serializable Spark Read refers to the process of reading data in Spark while ensuring that objects can be serialized and deserialized efficiently. Serialization, in simple terms, is the process of converting objects into a format that can be stored or transmitted. In Spark, this is crucial because tasks are distributed across multiple nodes, and data needs to be passed around efficiently.
Think of it like this: imagine you’re sending a package to a friend. You wouldn’t just toss everything into a box and hope for the best, right? You’d carefully wrap each item, ensuring it arrives intact. Serialization in Spark works the same way—it packages your data so it can travel safely between nodes in your cluster.
Without proper serialization, Spark jobs can slow down or even fail. Serializable Spark Read ensures that your data is handled correctly from the moment it’s read until it’s processed and stored. This is especially important when dealing with large datasets, where even small inefficiencies can have a significant impact on performance.
Why Serialization Matters in Spark
Serialization might sound like a technical term, but its importance in Spark can’t be overstated. When you’re working with distributed systems, data needs to move between different parts of the cluster. This movement requires serialization, and if it’s not done right, things can go south pretty fast.
Here are a few reasons why serialization matters:
Read also:Driverseat Philadelphia Your Ultimate Guide To The Citys Driving Experience
- Performance Optimization: Efficient serialization reduces the time and resources needed to transfer data, leading to faster Spark jobs.
- Scalability: As your data grows, so does the need for scalable serialization mechanisms. Serializable Spark Read ensures your system can handle increasing loads without breaking a sweat.
- Reliability: Proper serialization minimizes the risk of data corruption or loss during transmission, ensuring your results are accurate and trustworthy.
In short, serialization is the backbone of Spark’s ability to process massive amounts of data quickly and reliably. Without it, your workflows would grind to a halt.
Spark Serialization Mechanisms
Understanding Kryo and Java Serialization
Spark provides two main serialization mechanisms: Kryo and Java Serialization. Each has its own strengths and weaknesses, and choosing the right one depends on your specific use case.
Kryo Serialization: Kryo is a high-performance serialization library that’s faster and more efficient than Java Serialization. It’s the default choice for most Spark applications because it offers better performance and smaller serialized sizes. However, it requires you to register custom classes, which can be a bit of a hassle.
Java Serialization: Java Serialization is built into the Java language and is easier to use out of the box. While it’s slower and produces larger serialized objects compared to Kryo, it’s a good option if you’re working with legacy systems or don’t want to deal with the extra configuration required by Kryo.
When to Use Each Mechanism
Choosing between Kryo and Java Serialization depends on several factors:
- Use Kryo if you prioritize performance and are willing to put in the extra effort to configure it.
- Stick with Java Serialization if simplicity and compatibility are more important to you.
Ultimately, the best choice is the one that aligns with your project’s goals and constraints. Don’t be afraid to experiment and see which works best for your specific scenario.
Optimizing Spark Serialization
Optimizing Spark serialization is all about finding the right balance between performance and complexity. Here are a few tips to help you get the most out of Serializable Spark Read:
- Register Custom Classes: If you’re using Kryo, make sure to register any custom classes you’re serializing. This reduces the overhead of reflection and speeds up the serialization process.
- Use Immutable Objects: Immutable objects are easier to serialize and can lead to more efficient memory usage.
- Avoid Large Objects: Serializing large objects can slow down your Spark jobs. Try to break them down into smaller, more manageable pieces whenever possible.
By following these best practices, you can ensure that your Spark jobs run smoothly and efficiently, even when dealing with massive datasets.
Common Pitfalls to Avoid
Even with the best intentions, mistakes can happen. Here are a few common pitfalls to watch out for when working with Serializable Spark Read:
- Ignoring Serialization Overhead: Failing to account for serialization overhead can lead to slower Spark jobs and increased resource usage.
- Using the Wrong Serialization Mechanism: Choosing the wrong serialization mechanism for your use case can result in suboptimal performance.
- Not Registering Custom Classes: Forgetting to register custom classes with Kryo can lead to slower serialization and potential errors.
Being aware of these pitfalls and taking steps to avoid them will help you build more robust and efficient Spark workflows.
Best Practices for Serializable Spark Read
Now that you know the common mistakes to avoid, let’s talk about some best practices for Serializable Spark Read:
- Profile Your Serialization Performance: Use tools like Spark’s built-in monitoring to identify bottlenecks in your serialization process.
- Test Different Serialization Mechanisms: Experiment with both Kryo and Java Serialization to see which works best for your specific use case.
- Keep Your Code Clean and Modular: Writing clean, modular code makes it easier to optimize serialization and debug issues when they arise.
Following these best practices will help you build Spark workflows that are not only efficient but also maintainable and scalable.
Real-World Examples of Serializable Spark Read
Let’s take a look at some real-world examples of how Serializable Spark Read is used in practice:
Example 1: E-commerce Data Processing
In the world of e-commerce, processing customer data is critical for making informed business decisions. Serializable Spark Read can be used to efficiently process large datasets containing customer transactions, product reviews, and more. By optimizing serialization, companies can gain insights faster and make better decisions.
Example 2: Financial Data Analysis
Financial institutions rely on Spark to analyze vast amounts of data, from stock market trends to customer transactions. Serializable Spark Read ensures that this data is processed accurately and efficiently, enabling companies to detect patterns and anomalies that might otherwise go unnoticed.
Tools for Monitoring Serialization Performance
Monitoring your Spark jobs is essential for ensuring optimal performance. Here are a few tools you can use to monitor serialization performance:
- Spark UI: Spark’s built-in web UI provides valuable insights into job performance, including serialization metrics.
- Ganglia: Ganglia is a scalable distributed monitoring system that can be used to track resource usage across your Spark cluster.
- Apache Zeppelin: Zeppelin is a web-based notebook that allows you to visualize and analyze Spark job performance metrics.
By leveraging these tools, you can gain a deeper understanding of how your Spark jobs are performing and identify areas for improvement.
Future Trends in Spark Serialization
As technology continues to evolve, so too does Spark serialization. Here are a few trends to keep an eye on:
- Improved Serialization Libraries: New serialization libraries are being developed that promise even better performance and efficiency.
- Integration with Cloud Services: As more companies move to the cloud, Spark serialization will need to adapt to work seamlessly with cloud-based storage solutions.
- Artificial Intelligence and Machine Learning: AI and ML will play an increasingly important role in optimizing Spark serialization, enabling smarter and more efficient data processing.
Staying up-to-date with these trends will help you remain competitive in the ever-changing world of big data.
Conclusion: Take Your Spark Skills to the Next Level
And there you have it—your comprehensive guide to Serializable Spark Read. From understanding the basics of serialization to optimizing your Spark jobs and avoiding common pitfalls, you’re now armed with the knowledge to take your Spark skills to the next level.
Remember, mastering Serializable Spark Read isn’t just about improving performance—it’s about unlocking the full potential of your data. Whether you’re processing e-commerce transactions, analyzing financial data, or tackling any other big data challenge, Spark serialization is your secret weapon.
So, what are you waiting for? Dive in, experiment, and see what you can achieve. And don’t forget to share your experiences and insights in the comments below. Happy Spark-ing!



{kind=link}